¿Qué es un sistema RAG?
El Retrieval-Augmented Generation (RAG) es una técnica avanzada de inteligencia artificial que combina modelos de lenguaje de gran tamaño (LLM) con sistemas de recuperación de información. Este enfoque permite que los modelos generativos accedan a datos relevantes desde una base de conocimiento externa, mejorando la precisión y relevancia de las respuestas generadas sin necesidad de reentrenar el modelo.
Esquema del sistema RAG en byNeural
A continuación, te mostramos un esquema visual del flujo de trabajo del sistema RAG en byNeural:
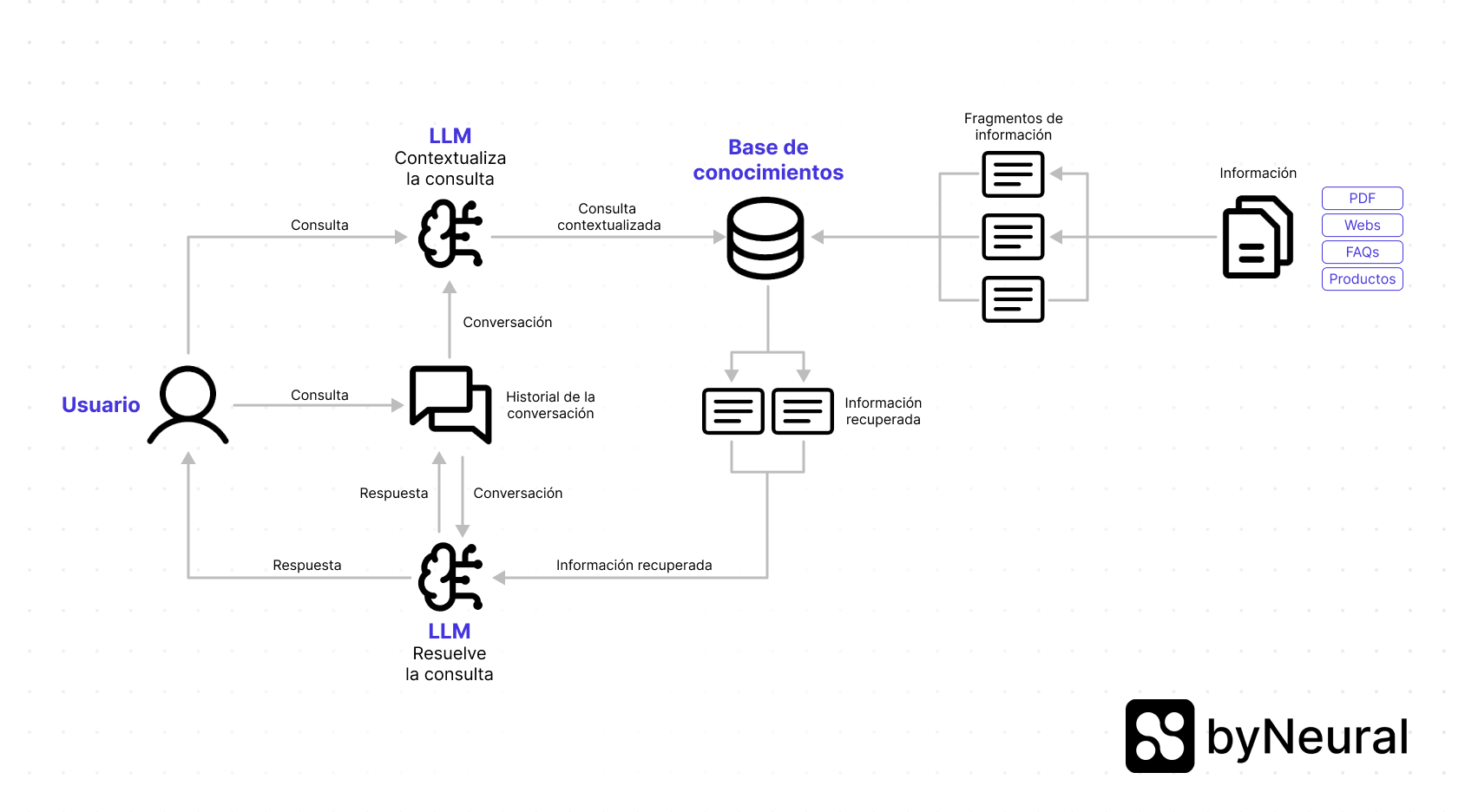
Este esquema representa una visión simplificada del sistema RAG en byNeural. En realidad, el sistema accede a dos bases de datos vectoriales:
- Información general: Proveniente de la Base de conocimientos, donde se almacenan documentos, FAQs y enlaces.
- Información de productos: Contenida en la sección de Widgets de productos.
Dependiendo de la consulta, el sistema puede acceder a una de las bases o incluso a ambas para ofrecer la respuesta más relevante.
Con un sistema RAG tan completo, en byNeural aseguramos que los asistentes virtuales ofrezcan respuestas más precisas y útiles, mejorando la experiencia del usuario y optimizando las interacciones.
¿Cómo funciona el RAG?
Para entender el funcionamiento del RAG, tomemos como ejemplo un asistente virtual de una tienda online de zapatillas deportivas:
1. El usuario hace una consulta
El proceso comienza con la interacción del usuario. Por ejemplo:
Usuario: "¿Tienes zapatillas deportivas azules y talla 42?"
2. Recuperación de información (Retrieval)
El sistema RAG busca información relevante en las bases de datos de la tienda, como catálogos de productos, inventarios y especificaciones.
Resultados recuperados:
Producto 1: Zapatillas deportivas azul oscuro, talla 42, precio: 120 €.
Producto 2: Zapatillas deportivas azul celeste, talla 42, precio: 95 €.
Producto 3: Zapatillas deportivas azul marino, talla 42, precio: 80 €.
El sistema selecciona únicamente los resultados más relevantes para la consulta del usuario.
Para que el sistema RAG funcione correctamente, es vital que la base de conocimientos esté bien estructurada, con información clara, actualizada y organizada.
Consulta nuestra guía para aprender a estructurar correctamente la Base de conocimientos.
3. Proveer la información al modelo generativo
La información recuperada se combina con la consulta original del usuario y se pasa al modelo generativo para procesarla.
Entrada al modelo generativo:
Consulta del usuario: "¿Tienen zapatillas deportivas en color azul y talla 42?"
Datos recuperados:
Producto 1: Zapatillas deportivas azul oscuro, talla 42, precio: 120 €.
Producto 2: Zapatillas deportivas azul celeste, talla 42, precio: 95 €.
Producto 3: Zapatillas deportivas azul marino, talla 42, precio: 80 €.
4. Respuesta del asistente virtual
El modelo generativo genera una respuesta clara y coherente basada en la consulta y los datos recuperados:
Asistente Virtual:
"Sí, tenemos varias opciones de zapatillas deportivas en color azul y talla 42:
- Zapatillas deportivas azul oscuro a un precio de 120 €.
- Zapatillas deportivas azul celeste por 95 €.
- Zapatillas deportivas azul marino por 80 €.
¿Le gustaría más información sobre alguna de estas opciones o desea proceder con la compra?"
¿Cómo funciona el RAG en byNeural?
En byNeural, el sistema RAG se utiliza para mejorar las respuestas del asistente virtual mediante el acceso a bases de conocimientos externas y la contextualización de las consultas.
1. Consulta del usuario
Supongamos que el usuario interactúa con el asistente y pregunta:
Usuario: "¿Cuánto tardan los envíos?"
Asistente: "Los envíos tardan entre 24 y 48 horas."
Usuario: "¿Y cuánto cuestan?"
Aunque la última consulta es breve, puede ser ambigua sin el contexto previo. Aquí es donde entra el LLM inicial para analizar la intención del usuario.
2. Contextualización de la consulta
El modelo de lenguaje (LLM) analiza la consulta en el contexto de la conversación previa. En este caso, entiende que el usuario está interesado en los costes de envío.
Consulta contextualizada: "Información sobre los costes de las opciones de envío."
Contextualizar la consulta es clave para garantizar que las respuestas sean precisas y relevantes. Sin esta etapa, el asistente podría generar respuestas ambiguas o incorrectas. La capacidad del LLM para considerar el historial de la conversación es esencial para entender el verdadero propósito de las consultas del usuario.
3. Recuperación de información (Retrieval)
El sistema accede a la base de conocimientos, que puede incluir bases de datos de productos y precios o documentos como políticas de envío.
Resultados recuperados:
"Envío estándar: 5 €."
"Envío exprés: 10 €."
4. Generación de respuesta
El modelo generativo utiliza la información recuperada junto con la consulta original para generar una respuesta:
Asistente Virtual:
"El coste del envío estándar es de 5 €, mientras que el envío exprés tiene un coste de 10 €. ¿Hay algo más en lo que le pueda ayudar?"
Beneficios del enfoque RAG aplicado en byNeural
El uso de RAG en byNeural ofrece ventajas clave:
- Interpretación precisa de la intención del usuario: El contexto asegura que incluso preguntas ambiguas sean entendidas correctamente.
- Acceso a información actualizada y relevante: La recuperación de datos garantiza que las respuestas estén basadas en información específica y actual.
- Respuestas coherentes y naturales: El modelo generativo combina los datos recuperados con el historial de la conversación para proporcionar respuestas claras y bien estructuradas.